Hello,
I use MarkSubStringW function to highlight search result in RichViewEdit. but there is a problem in Arabic texts which have diacritics.
I want to search Arabic text that contains diacritics and highlight the matched words but I don't want the user to type the words with diacritics, because most people don't use them when typing.
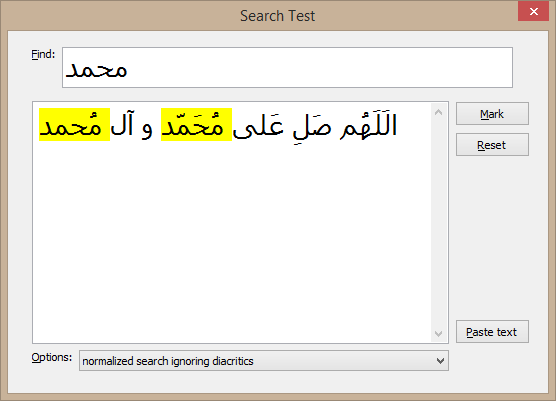
But what I want to happen is that if the text is " الَلَهُم صَلِ عَلى مُحَمّد و آل مُحمد " and user searches for " محمد " it should highlight "مُحَمّد " and " مُحمد " regardless of all the diacritics.
Speed of search and highlight very important for me.
please help.
Highlight search result in Arabic text
-
Sergey Tkachenko
- Site Admin
- Posts: 17559
- Joined: Sat Aug 27, 2005 10:28 am
- Contact:
Sorry, I do not understand Arabic, so I am afraid I cannot modify this function for you.
However, if you look in MarkSearch.pas, you will see that it has
function StrPosW(s, SubStr: PRVUnicodeChar): PRVUnicodeChar;
This function is used to find SubStr in s.
If you can modify it so that it handles diacritics, I can create a modified version of MarkSubStringW.
Since the found substring may have a different length than SubStr, this function must return not only the found position (SubStrPos), but also length of the text to highlight (Len).
procedure StrPosWEx(s, SubStr: PRVUnicodeChar; var SubStrPos: PRVUnicodeChar; Len: Integer);
However, if you look in MarkSearch.pas, you will see that it has
function StrPosW(s, SubStr: PRVUnicodeChar): PRVUnicodeChar;
This function is used to find SubStr in s.
If you can modify it so that it handles diacritics, I can create a modified version of MarkSubStringW.
Since the found substring may have a different length than SubStr, this function must return not only the found position (SubStrPos), but also length of the text to highlight (Len).
procedure StrPosWEx(s, SubStr: PRVUnicodeChar; var SubStrPos: PRVUnicodeChar; Len: Integer);
Thank you,
I found this code in JavaScript:
if RichViewEdit has a function to get words of text in array for example, and has another function to highlight a word with index, it is possible to convert the java code to Delphi.
I found this code in JavaScript:
Code: Select all
function stripDiacritics(rawString) {
return rawString.replace(/ُ|ِ|َ|ٍ|ً|ّ/g,"");
}
function highlight() {
var textblock = document.getElementById('textSection').innerHTML;
var words = textblock.split(' ');
var resultText = '';
for (var i=0; i < words.length; i++) {
var strippedWord = stripDiacritics(words[i]);
if (strippedWord == 'محمد') {
resultText += ' <span class="highlighted">'+words[i]+'</span>';
}
else {
resultText += ' '+words[i];
}
}
document.getElementById('textSection').innerHTML = resultText;
}-
Sergey Tkachenko
- Site Admin
- Posts: 17559
- Joined: Sat Aug 27, 2005 10:28 am
- Contact:
Well, this solution is far from optimal:
- it requires disassembling strings to words
- works only for whole words
- recreates the original string, even if nothing was found.
However, I can see how it could be implemented. We can create a function removing all diacritics from string, and making a map of character positions from the new string to the original string. Then we can search for a substring in the processed string, and, if found, use the map to find the position of highlighting in the original document.
It's not very difficult, but is not a trivial as well. We are currently busy on releasing Report Workshop components, so I cannot do it right now.
But I'll try to implement it later in this week.
I think it's an interesting option to add to the regular SearchText method of TRichView as well.
- it requires disassembling strings to words
- works only for whole words
- recreates the original string, even if nothing was found.
However, I can see how it could be implemented. We can create a function removing all diacritics from string, and making a map of character positions from the new string to the original string. Then we can search for a substring in the processed string, and, if found, use the map to find the position of highlighting in the original document.
It's not very difficult, but is not a trivial as well. We are currently busy on releasing Report Workshop components, so I cannot do it right now.
But I'll try to implement it later in this week.
I think it's an interesting option to add to the regular SearchText method of TRichView as well.
Well, Thank you Sergey,
There is another way in my mind. that way is difining and using "?" & "*" or other characters in searching and highlighting, like searching in Windows.
For example we can define "*" character instead of diacritics in MarkSubStringW function, then when user typed any words to search we add this character after each characters of user word and send new string to the function. like this:
Is it a good way?
There is another way in my mind. that way is difining and using "?" & "*" or other characters in searching and highlighting, like searching in Windows.
For example we can define "*" character instead of diacritics in MarkSubStringW function, then when user typed any words to search we add this character after each characters of user word and send new string to the function. like this:
Code: Select all
function CreateNewText (OriginalText : string) : string;
var
i : Integer;
s : string;
begin
s := OriginalText[1];
for i := 2 to Length(OriginalText) do
s := s + '*' + OriginalText[i];
Result := s;
end;
procedure TForm1.btn1Click(Sender: TObject);
begin
MarkSubStringW(CreateNewText(Edit1.Text), clRed, clYellow, False, False, RichViewEdit1)
end;-
Sergey Tkachenko
- Site Admin
- Posts: 17559
- Joined: Sat Aug 27, 2005 10:28 am
- Contact:
Searching by templates (or even regular expressions) would be an interesting feature, but it's not easy to implement, and it would be an overkill for a simple task of ignoring diacritics.
Also, if '*' means any number of characters, it may match not only diacritic characters, but any, may be very long, text.
Also, if '*' means any number of characters, it may match not only diacritic characters, but any, may be very long, text.
Hello Sergey, Did you implement it?Sergey Tkachenko wrote:Well, this solution is far from optimal:
- it requires disassembling strings to words
- works only for whole words
- recreates the original string, even if nothing was found.
However, I can see how it could be implemented. We can create a function removing all diacritics from string, and making a map of character positions from the new string to the original string. Then we can search for a substring in the processed string, and, if found, use the map to find the position of highlighting in the original document.
It's not very difficult, but is not a trivial as well. We are currently busy on releasing Report Workshop components, so I cannot do it right now.
But I'll try to implement it later in this week.
I think it's an interesting option to add to the regular SearchText method of TRichView as well.
Hi Sergey,Sergey Tkachenko wrote:Sorry, I do not understand Arabic, so I am afraid I cannot modify this function for you.
However, if you look in MarkSearch.pas, you will see that it has
function StrPosW(s, SubStr: PRVUnicodeChar): PRVUnicodeChar;
This function is used to find SubStr in s.
If you can modify it so that it handles diacritics, I can create a modified version of MarkSubStringW.
Since the found substring may have a different length than SubStr, this function must return not only the found position (SubStrPos), but also length of the text to highlight (Len).
procedure StrPosWEx(s, SubStr: PRVUnicodeChar; var SubStrPos: PRVUnicodeChar; Len: Integer);
The Arabic diacritics are:
#1611
#1612
#1613
#1614
#1615
#1616
#1617
#1618
In Arabic Text, The diacritics are always placed after letters(not before), so the StrPosWEx function must first remove this diacritics from S then Return the address of the first occurence of SubStr in S and length of the text to highlight.
-
Sergey Tkachenko
- Site Admin
- Posts: 17559
- Joined: Sat Aug 27, 2005 10:28 am
- Contact:
Sorry, I did not complete this work yet.
I want to write an universal search function for ignoring diacritics, not only for Arabic.
Actually, in any language, diacritic characters follow the base character.
There is one problem, though. The same text can be written differently - in decomposed form (where base characters and diacritic characters are separate) and in precomposed form (where they are represented as a single character).
I want to write an universal search function for ignoring diacritics, not only for Arabic.
Actually, in any language, diacritic characters follow the base character.
There is one problem, though. The same text can be written differently - in decomposed form (where base characters and diacritic characters are separate) and in precomposed form (where they are represented as a single character).
Yes this is a problem but solving it not very difficult, I am impatiently waiting for your help.Sergey Tkachenko wrote:There is one problem, though. The same text can be written differently - in decomposed form (where base characters and diacritic characters are separate) and in precomposed form (where they are represented as a single character).
-
Sergey Tkachenko
- Site Admin
- Posts: 17559
- Joined: Sat Aug 27, 2005 10:28 am
- Contact:
Well, this problem may be not very difficult, but still requires attention and accuracy. Windows includes NormalizeString function that does this work, but this function does not allow to get a correspondence between characters of an original and a resulting strings.
Finally, I created a modification of MarkSubStringW with additional Options parameter. It may include:
rvmsoNormalize - normalizes strings before searching
rvmsoStripDiacritic - normalizes strings and removes diacritics before searching.
Download the modified unit and the demo:
http://www.trichview.com/support/files/ ... search.zip
(for Arabic test, assign BiDiMode property in the demo)
Finally, I created a modification of MarkSubStringW with additional Options parameter. It may include:
rvmsoNormalize - normalizes strings before searching
rvmsoStripDiacritic - normalizes strings and removes diacritics before searching.
Download the modified unit and the demo:
http://www.trichview.com/support/files/ ... search.zip
(for Arabic test, assign BiDiMode property in the demo)
-
Sergey Tkachenko
- Site Admin
- Posts: 17559
- Joined: Sat Aug 27, 2005 10:28 am
- Contact:
Examples:
Search with ignored diacritic characters, your text:
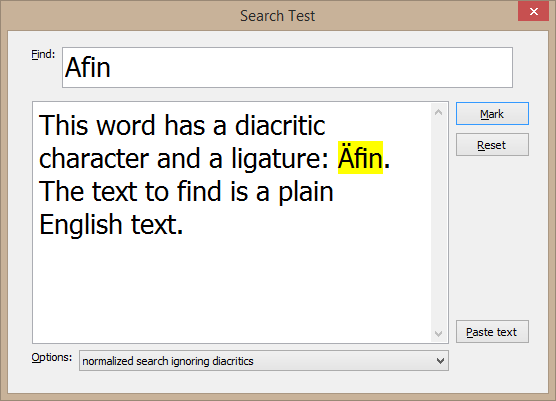
Search with ignored diacritic characters, Western text
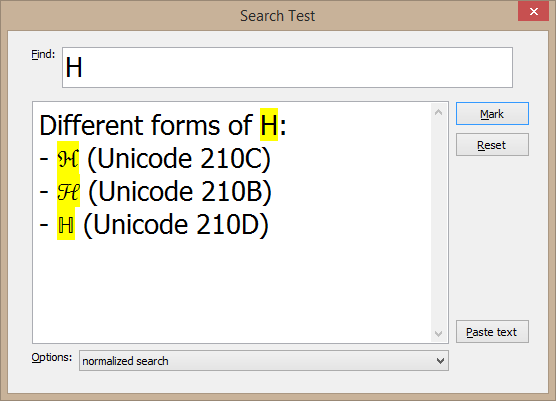
The Unicode normalization introduces some interesting side effects.
For example, different forms of the same character can be found:
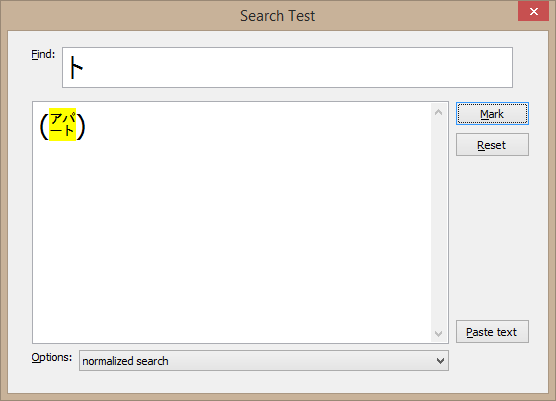
Or you can search "inside" composite characters:
Please check if everything is ok. If yes, I'll include this change in RichViewActions, and add the same feature to TRichView.SearchText
Search with ignored diacritic characters, your text:
Search with ignored diacritic characters, Western text
The Unicode normalization introduces some interesting side effects.
For example, different forms of the same character can be found:
Or you can search "inside" composite characters:
Please check if everything is ok. If yes, I'll include this change in RichViewActions, and add the same feature to TRichView.SearchText
-
Sergey Tkachenko
- Site Admin
- Posts: 17559
- Joined: Sat Aug 27, 2005 10:28 am
- Contact:
I uploaded a fixed version.
In addition to an important fix in the functions themselves, it has the following changes:
1) compatibility with XE5 and older is restored
2) Boolean parameters (IgnoreCase and WholeWords) are removed, the corresponding options are added in the Options parameter instead
3) WinAPI NormalizeString function is now linked dynamically, rvmsoNormalize and rvmsoStripDiacritic options are processed only if this function is available.
It is available starting from Windows Vista. For XP, it requires a separate download https://msdn.microsoft.com/en-us/librar ... s.85).aspx
In addition to an important fix in the functions themselves, it has the following changes:
1) compatibility with XE5 and older is restored
2) Boolean parameters (IgnoreCase and WholeWords) are removed, the corresponding options are added in the Options parameter instead
3) WinAPI NormalizeString function is now linked dynamically, rvmsoNormalize and rvmsoStripDiacritic options are processed only if this function is available.
It is available starting from Windows Vista. For XP, it requires a separate download https://msdn.microsoft.com/en-us/librar ... s.85).aspx
Thank you very very much Sergey, I will check it and get you feedback.Sergey Tkachenko wrote:I uploaded a fixed version.
In addition to an important fix in the functions themselves, it has the following changes:
1) compatibility with XE5 and older is restored
2) Boolean parameters (IgnoreCase and WholeWords) are removed, the corresponding options are added in the Options parameter instead
3) WinAPI NormalizeString function is now linked dynamically, rvmsoNormalize and rvmsoStripDiacritic options are processed only if this function is available.
It is available starting from Windows Vista. For XP, it requires a separate download https://msdn.microsoft.com/en-us/librar ... s.85).aspx
Two question:
1. if we set options to rvmsoNormalize or rvmsoStripDiacritic, is it possible to define new rule to normalization of string?
for example in Arabic text we have this two characters: ه and ة which are not same characters but if users want to search for a word which it's last character is ة like فاطمة, sometimes they type ه instead of ة like this: فاطمه. is it possible to highlight فاطمة when user types فاطمه ?
2. I want to get the Position of marked words by MarkSubStringW as a list to move caret position to them by clicking on NextButton and PrevButton. I should modify MarkSubStringW to get this list or RichView has a function to move caret position to highlighted word position?
-
Sergey Tkachenko
- Site Admin
- Posts: 17559
- Joined: Sat Aug 27, 2005 10:28 am
- Contact:
This code uses WinAPI NormalizeString to get NFKD (compatibility decomposition normalization form) of text, when these normalized texts are compared.
While this type of normalization treats different forms of a character as the same, for example (①= 1), it still treats ه and ة as different characters.
So you need to patch the function manually.
Find
Add after:
Find:
Add after:
While this type of normalization treats different forms of a character as the same, for example (①= 1), it still treats ه and ة as different characters.
So you need to patch the function manually.
Find
Code: Select all
Len2 := RVNormalizeString(NormalizationKD, Ptr, Len,
PtrDest, Length(Result));Code: Select all
if Ptr^ = 'ة' then
PtrDest^ := 'ه';Code: Select all
Len2 := RVNormalizeString(NormalizationKD, Ptr, Len,
PtrDest, Length(Result) div 2);Code: Select all
if Ptr^ = 'ة' then
PtrDest^ := 'ه';